Characterizing COVID-19 Misinformation Communities Using a Novel Twitter Dataset
- Authors: Memon & Carley (Carnegie Mellon University)
- Publication, Year: Preprint (Sep, 2020)
- Link
Characterizing COVID-19 Misinformation Communities Using a Novel Twitter DatasetSummaryAnalysis perspectiveData CollectionData annotationTopics covered in the datasetAnalysis and DiscussionIdentifying communitiesData AugmentationNetwork AnalysisBot DetectionSociolinguistic AnalysisNarrative Discourse StructureToneLinguistic formalityVaccination StanceLimitations
Summary
In this paper, Memon & Carley create a novel dataset of tweets that are focused on a specific group of users that they identify as "informed" and "misinformed." They investigate these community's network structure and linguistic patterns. They conclude that their analyses suggests:
COVID-19 misinformed communities are denser, and more organized than informed communities
- Possibility that a high volume of the misinformation originates from a disinformation campaign
A large majority of misinformed users may be anti-vaxxers
COVID-19 informed users tend to use more narratives than misinformed users (based on socio-linguistic analyses via LIWC)
Dataset name: CMU-MisCOV19
Analysis perspective
In this study, we do not characterize the misinformation content directly. Instead, we conduct a set of analyses to understand and characterize the competing COVID-19 communities through their content, and content-sharing behaviors and interactions.
Data Collection
They gather tweets on the three days below based on a set of keywords. I assume they used Twitters filter API, however, it's not clear in the paper if that's true.
- March 29th, 2020
- June 15th, 2020
- June 24th 2020
Each of these collections extracted a set of tweets from their corresponding week
It's not clear to me what this means… Are they collecting tweets for that week, or for just that day? Are they getting tweets on that day and then extracting retweet cascades for the following week? No idea.
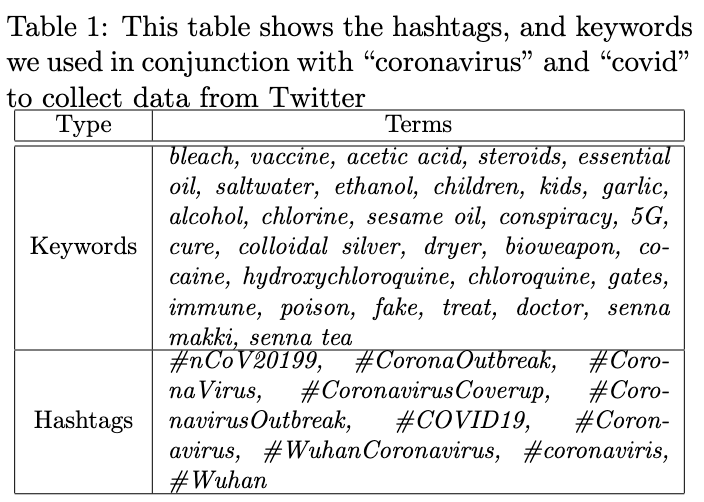
Data annotation
They had 1 person annotate 4,573 tweets (phase 1) and another 6 people annotate 651 more tweets which were randomly assigned to them (phase 2).
Below is the breakdown of tweets based on their annotation.
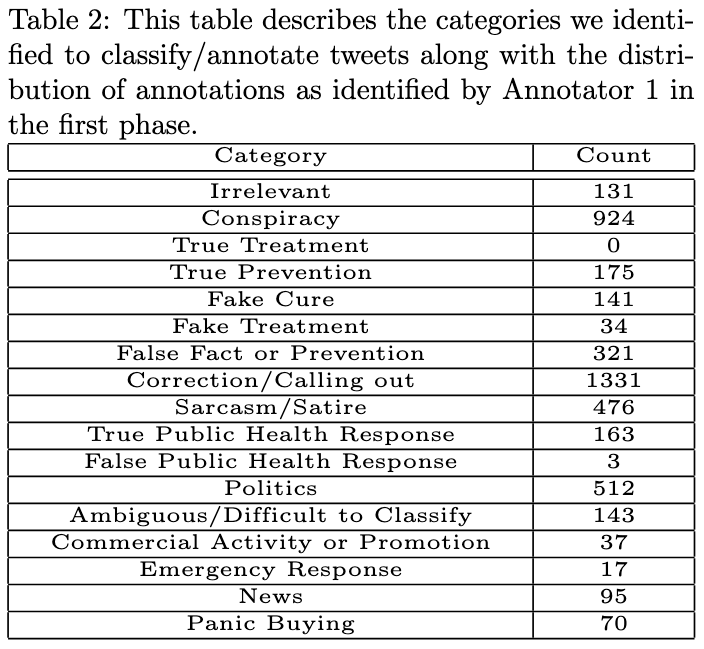
Topics covered in the dataset
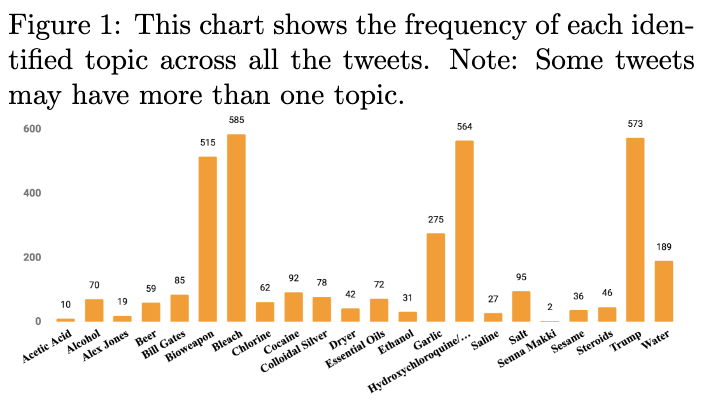
Analysis and Discussion
Identifying communities
To identify informed vs. misinformed communities, they added valence labels of either +1 or -1 to some of the above categories and then calculated a weight sum of all valence scores for all users in the data set. If they get a positive score, they are informed and if they get a score below 0 they are misinformed.
The above process led to the below breakdown:
- Informed: 47% (1,697 users)
- Misinformed: 29% (1,043 users)
- Ambiguous/Irrelevant: 24% (889 user)
Data Augmentation
Once they identified these users, they pulled all of their most recent tweets which included the words "corona" and (?) "covid". This yields:
- Total tweets: 330,609
- Average tweet per user: 91
Network Analysis
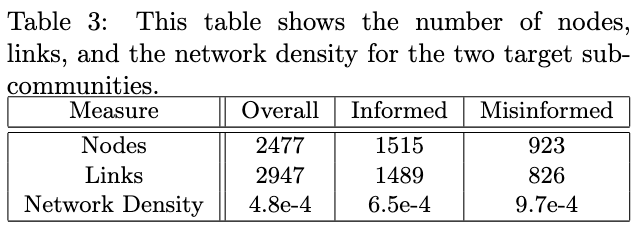
They create retweet, mention, and reply networks for each of the identified communities and combine them together.
Calculate network density for each of the two groups.
Network density: the ratio of actual connections and potential connections.
They use ORA-PRO to plot the network graphs below.


They claim both groups display echo-chambers with an increased density compared to the overall group — "as shown in table 3."
Bot Detection
They use Bot-Hunter for their bot analysis (precision of .957 and recall of .704).
Use probability >= .75 to identify bots.
Conduct a z-test for the difference in proportion of bots () between the informed vs misinformed groups. Results are in table 4.
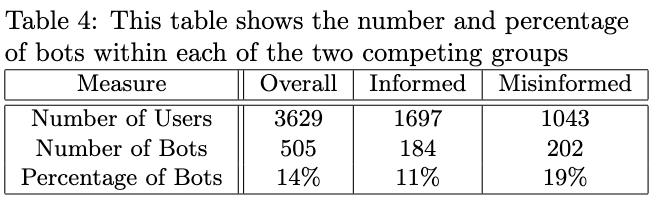
They find comparing the proportion of misinformed vs informed communities to be statistically significant ().
Sociolinguistic Analysis
The use the Linguistic Inquiry Word Count (LIWC) program to understand linguistic differences between the groups.
LIWC is a text analysis tool which looks at the different lexical categories each of which is psychologically meaningful. For a given text, LIWC calculated the percentage of each LIWC categories. All of these categories are based on word counts.
They run this program on the timeline of members for each group — only using tweets related to covid — removing all accounts which were identified as a bot from the earlier analysis.
Percentages are normalized by the size of data for each user.
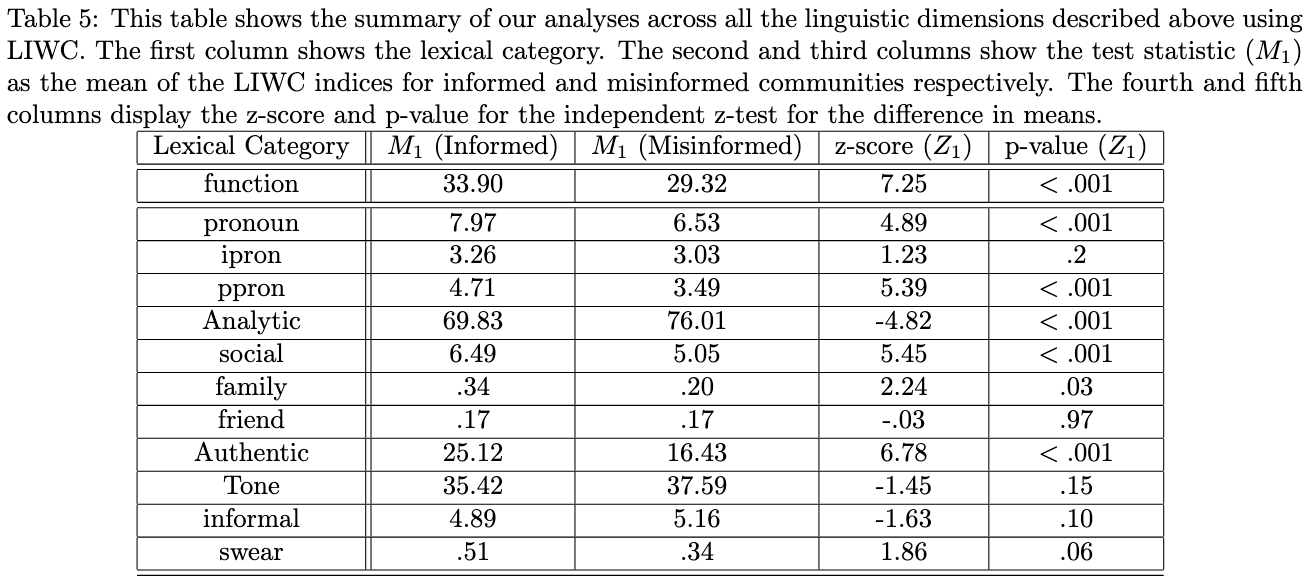
Narrative Discourse Structure
Based on the LIWC results, they conclude:
Informed users in the COVID-19 discourse use significantly more pronouns, more functional words, mention more family-related keywords, are less analytical, and more authentic and honest in comparison to misinformed users. All of these suggest that informed users may use many more narratives than misinformed users.
Tone
Based on the LIWC results, they conclude:
According to the definition of LIWC, the higher the tone index, the more positive the tone. Indices less than 50 typically suggest a more negative tone. While we do not see significant differences in the emotional tone of the competing groups, we find both the communities to be highly negative.
Linguistic formality
Based on the LIWC results related to the swear and informal categories, they conclude:
… it can be observed that misinformed users tend to be more informal than informed users, though informed users tend to use more swear words than misinformed users. This is intuitive as many of our informed users post corrective or sarcastic tweets to call out misinformation. However, our results are not significant, and, hence inconclusive.
Vaccination Stance
To understand how the different groups addressed the vaccination discussion online, they collect all tweets from the two groups that mention "vaccines" in the past. They then collect a user-to-hashtag co-occurence network. We then use the valence of those hashtags obtained via a label-propagation-based method.
The stance of a member as "provaxx" or "antivaxx" is then taken as the weighted sum of the valences of the hashtags they shared.
If the weights sum is greater than 0, we identify the member as pro-vaxxer, and if the weighted sum is less than 0, we identify the member as anti-vaxxer.
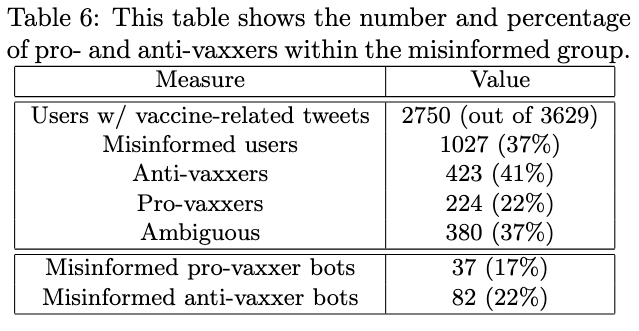
As shown in table 6, 17% of the misinformed pro-vaxxers are bots, which is significantly lower than the proportion of bots within the misinformed ant-vaxxers. The first thing this suggests is that a big chunk of the VOID-19 misinformation online may in fact be disinformation, and hence, intentional.
Limitations
(As outlined by the authors)
Most of the data has been annotated by a single annotator
All analyses are correlational
Their data collection method (taking snapshots of activity across three weeks, and then augmenting with different tweets, hashtags, etc.) means they look at changes over time
- Because of this, the narrative analysis may be hindered by the lack of an ability to see things change over time or the true diversity of stories
Bot-analysis based on a second-level inference from a bot trained on different data
The "stance" analysis on COVID vaccines is a bit more nuances than the way that they analyze it
Notes by Matthew R. DeVerna